- Published on
Should Database DDL Strive for ACID Too? (Award-Winning)
- Authors

- Name
- Bryce Yu
- @earayu
This article won the first prize in the Alibaba Cloud Database Pioneer Essay Contest.
背景
纵观数据库领域数十年来的发展,关系型数据库脱颖而出的一个重要原因是,它支持用户灵活地定义和修改“数据模型”。 模型演进(schema evolution)是其中的关键问题,在SQL-92标准中提出了一系列用于描述关系模型的语法,也就是各种DDL语句。DDL通常也是各个数据库厂商夹带私货最多的地方,各家数据库都会推出很多自己独有的DDL语法,以支持更灵活的模型演进。 但是,DDL的执行时机却非常不灵活。数据库的DDL通常被视为一个危险操作,很多时候只允许在运维窗口或者业务低峰期进行,这与当今应用“always online”的趋势显得格格不入。 究其原因,主要在于以下几点:
- DDL会“锁表”,可能严重阻塞其他事务的执行。
- DDL可能消耗大量的硬件资源,如CPU、IOPS。
- DDL不是Crash Safe的,可能导致元数据、甚至物理数据文件损坏。
不过,与其把上述问题独立地视为DDL的各种“罪状”,不如把它们放到一个统一的维度中讨论。从笔者的观点来看,这些问题全都可以归咎于DDL的事务性做的不够好。 所以,本文着眼于DDL的ACID特性,讨论PolarDB-X如何面对以及解决这些问题。
DDL是否需要事务的ACID特性?
虽然SQL-92标准在讨论事务的时候没有区分DML和DDL,但实现了事务性DDL的数据库却屈指可数。各个数据库(如MySQL)通常的做法是,在DDL语句前后加上2个隐式的commit。但这是否能说明,单个DDL语句能够满足事务的ACID特性呢?实际上也并不尽然,比如MySQL在5.6版本才支持DDL和DML的并发执行(需要隔离性),在8.0版本才实现了DDL的原子性。 我们先来看看,DDL的ACID分别意味着什么:
原子性:一条DDL语句通常对应了一系列的操作,比如创建/删除数据文件,修改元数据,刷新内存中的数据等。原子性要求这些操作,要么全部生效,要么全部不生效。原子性的实现需要考虑数据库的Crash Recovery,通常做法是使用Write-Ahead Log。MySQL 8.0引入的innodb_ddl_log本质上就充当了WAL的角色,PolarDB-X 2.0的DDL执行引擎也使用类似的方式确保DDL的Crash-Safe。
一致性:数据模型需要从一个一致性状态变成另一个一致性状态。在这中间过程中,通常需要多个操作,所以在变更过程,数据模型可能处于不一致的状态。需要引入隔离性来确保DML永远看到一致的数据模型,MySQL 5.6之前直接禁止DML和DDL的并发。影响一致性的另一个问题是数据库内核BUG,特别是当复杂的DDL语句组合起来的时候,容易造成元数据错误。
隔离性:MySQL 5.6之后允许Online DDL,但还是会在关键节点上要求DDL获取MDL的X锁。这是DDL必须在低峰期执行的重要原因之一。根据并发控制理论我们知道,相比于使用“锁”来做并发控制,更好的方式是使用MVCC,这样能使得读写元数据不需要再获取MDL锁,所以PolarDB-X引入了MVCC式的元数据模型[1][2]。
持久性:持久性要求DDL一旦返回“成功”,所有它带来的变更都是持久化的。对于普通DML事务来说,持久性通常和原子性一起由复杂WAL机制保证。不过考虑到DDL通常是低频操作,所以实现的时候也可以使用No-Steal/Force的buffer pool管理策略确保持久性。当然,也可以直接将元数据存储系统建立在更高纬度上,比如一个支持事务的存储系统。
可以看到,MySQL虽然不支持事务性DDL,但是一直在改进DDL在ACID方面的能力。最显著的是5.6引入的Online DDL能力,以及8.0引入的原子性DDL能力。
如何实现DDL的原子性和持久性(Crash Safe)?
事务是Crash Recovery的基本单位,而实现事务原子性和持久性的基本手段是WAL。在讨论PolarDB-X如何实现原子性和持久性之前,我们先看一下MySQL 8.0是怎么做的。
MySQL
在MySQL 8.0之前,DDL不能做到Crash Safe的主要问题有:
- 元数据存储在多个不同的地方,比如元数据文件、不支持事务的数据表、不同的存储引擎中。MySQL 8.0版本将所有元数据存储统一到了支持事务的InnoDB存储引擎中。
- 崩溃恢复后没有足够的信息恢复DDL(继续执行或回滚),MySQL 8.0版本引入innodb_ddl_log系统表充当UNDO LOG和REDO LOG。
以Drop Table为例,MySQL 8.0的大致执行过程如下:
- 在一个事务中,删除表的元数据,并在innodb_ddl_log表中写入一条记录“DELETE SPACE t1”。
- 提交事务。此时相当于Drop Table T1操作的commit point,一旦提交成功,则无法回滚。
- 最后会根据innodb_ddl_log表中的信息:删除数据文件,最后清理innodb_ddl_log表。
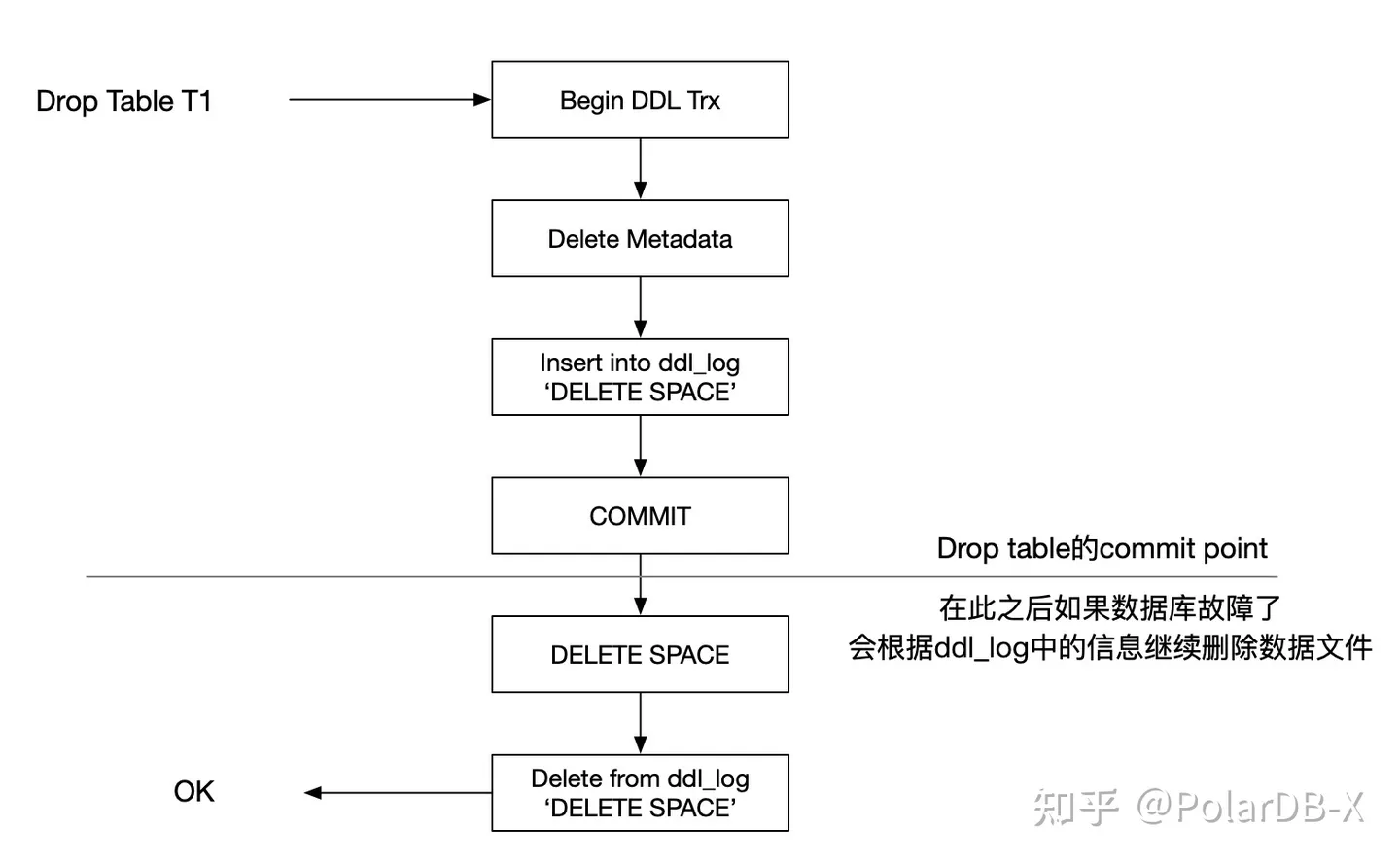 由此可见,WAL加上对应的“幂等操作”是实现Crash Safe的关键。当数据库崩溃恢复的时候,可以根据WAL中的信息来决定继续执行或者回滚。
由此可见,WAL加上对应的“幂等操作”是实现Crash Safe的关键。当数据库崩溃恢复的时候,可以根据WAL中的信息来决定继续执行或者回滚。 PolarDB-X
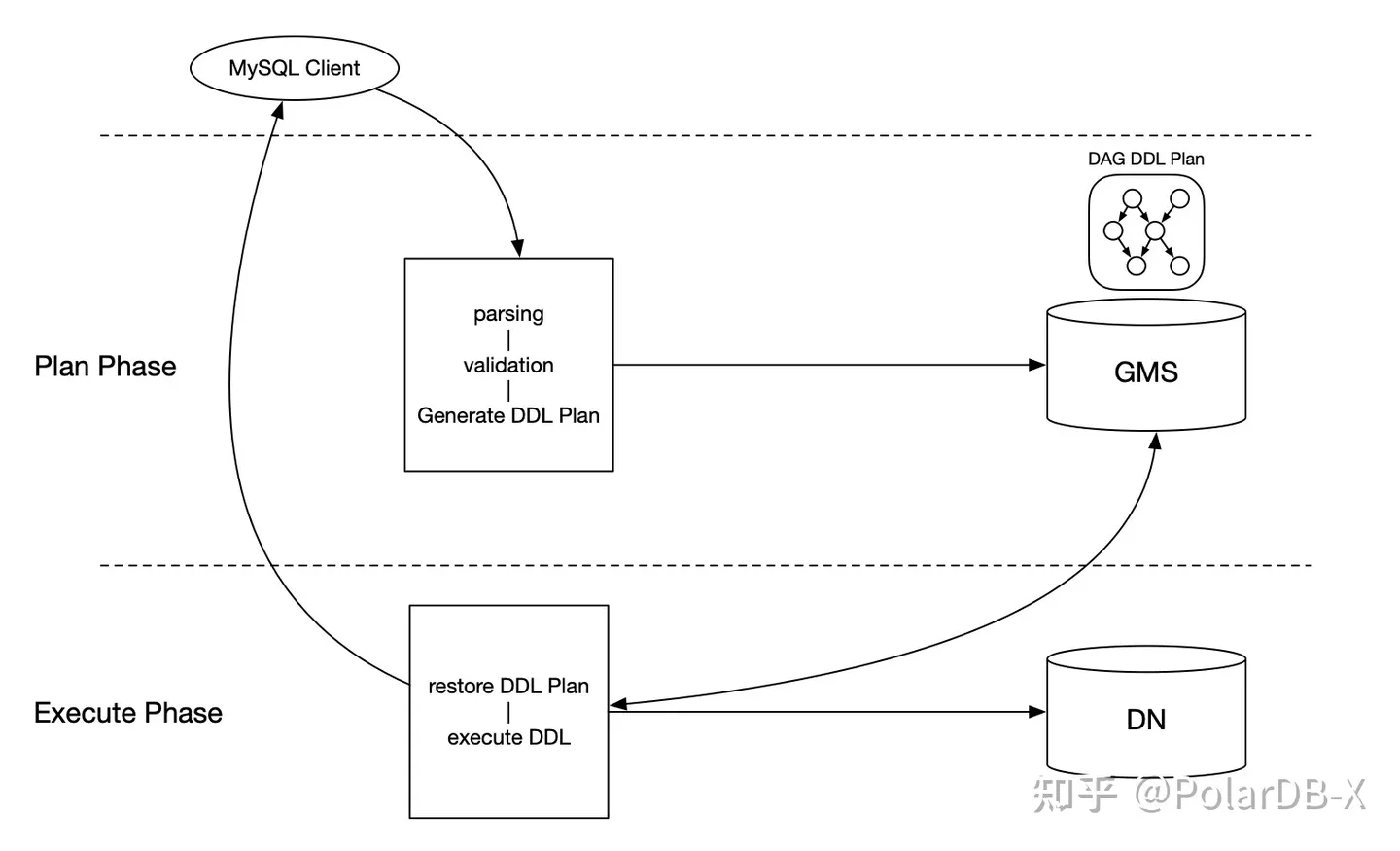 DAG DDL Plan中的每个Task都是自包含的,它拥有所有执行所需要的数据,所以实际上每个Task都是可以独立执行的,只不过DDL的正确性依赖于Task执行顺序,我们用DAG图描述Task之间的依赖关系。同时,这一架构也使得DDL的并发执行和远程执行成为可能。 依旧以Drop Table为例,我们看看PolarDB-X的执行流程:
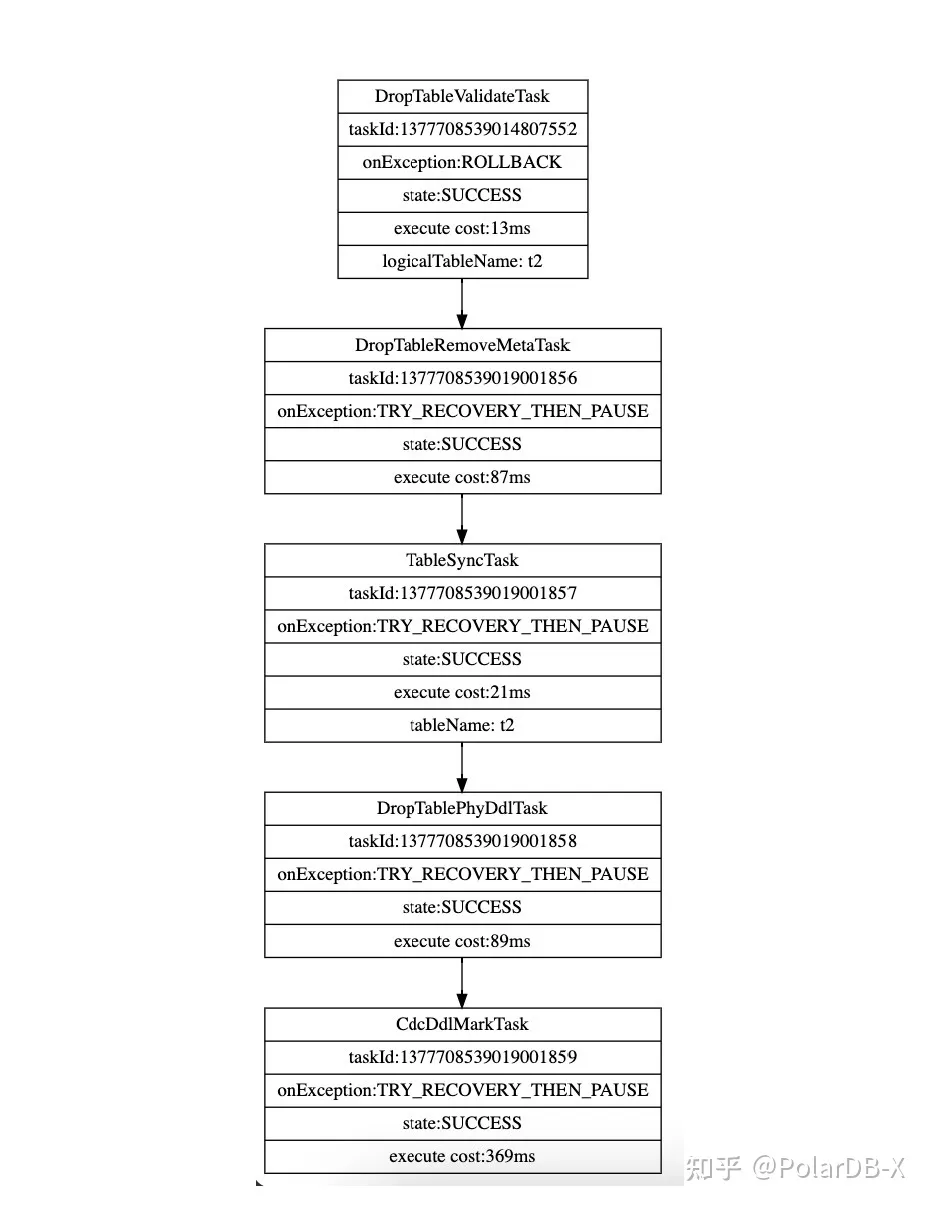
DAG DDL Plan中的每个Task都是自包含的,它拥有所有执行所需要的数据,所以实际上每个Task都是可以独立执行的,只不过DDL的正确性依赖于Task执行顺序,我们用DAG图描述Task之间的依赖关系。同时,这一架构也使得DDL的并发执行和远程执行成为可能。 依旧以Drop Table为例,我们看看PolarDB-X的执行流程:- 校验表是否可删除
- 删除表的元数据,这一步为这个DDL的commit point。它会在同一个事务中删除元数据并修改这个Task的状态为“SUCCESS”。在第2步之后如果某个Task失败,会自动不断地重试。
- 在集群内广播元数据刷新。此时如果有一个老事务,它还能读写这张表,但是所有新事务都会认为表不存在。
- 删除物理表
- 同步CDC消息
 一旦我们拥有了DDL Crash Safe的能力,我们就可以基于它实现一些非常实用的功能:相较于MySQL,PolarDB-X可以更灵活地控制DDL的执行。 还记得开头提出的一个问题吗?DDL可能会占用很多的CPU或IOPS等硬件资源。 比如给一个超级大表添加索引可能需要数天才能执行完成,如果是MySQL则只能一次性执行,在业务低峰期执行不完,但是在高峰期又会占用硬件资源。 但PolarDB-X可以随时暂停任务,恢复任务,每天在业务低峰期执行。
一旦我们拥有了DDL Crash Safe的能力,我们就可以基于它实现一些非常实用的功能:相较于MySQL,PolarDB-X可以更灵活地控制DDL的执行。 还记得开头提出的一个问题吗?DDL可能会占用很多的CPU或IOPS等硬件资源。 比如给一个超级大表添加索引可能需要数天才能执行完成,如果是MySQL则只能一次性执行,在业务低峰期执行不完,但是在高峰期又会占用硬件资源。 但PolarDB-X可以随时暂停任务,恢复任务,每天在业务低峰期执行。 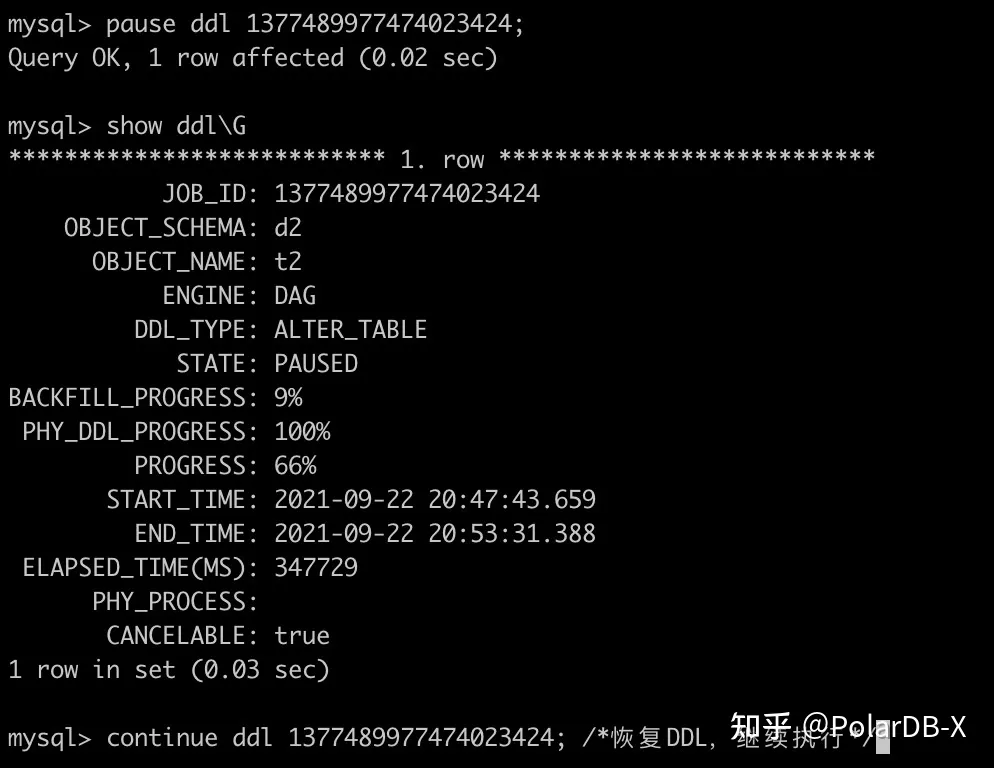
如何实现DDL的隔离性和一致性?
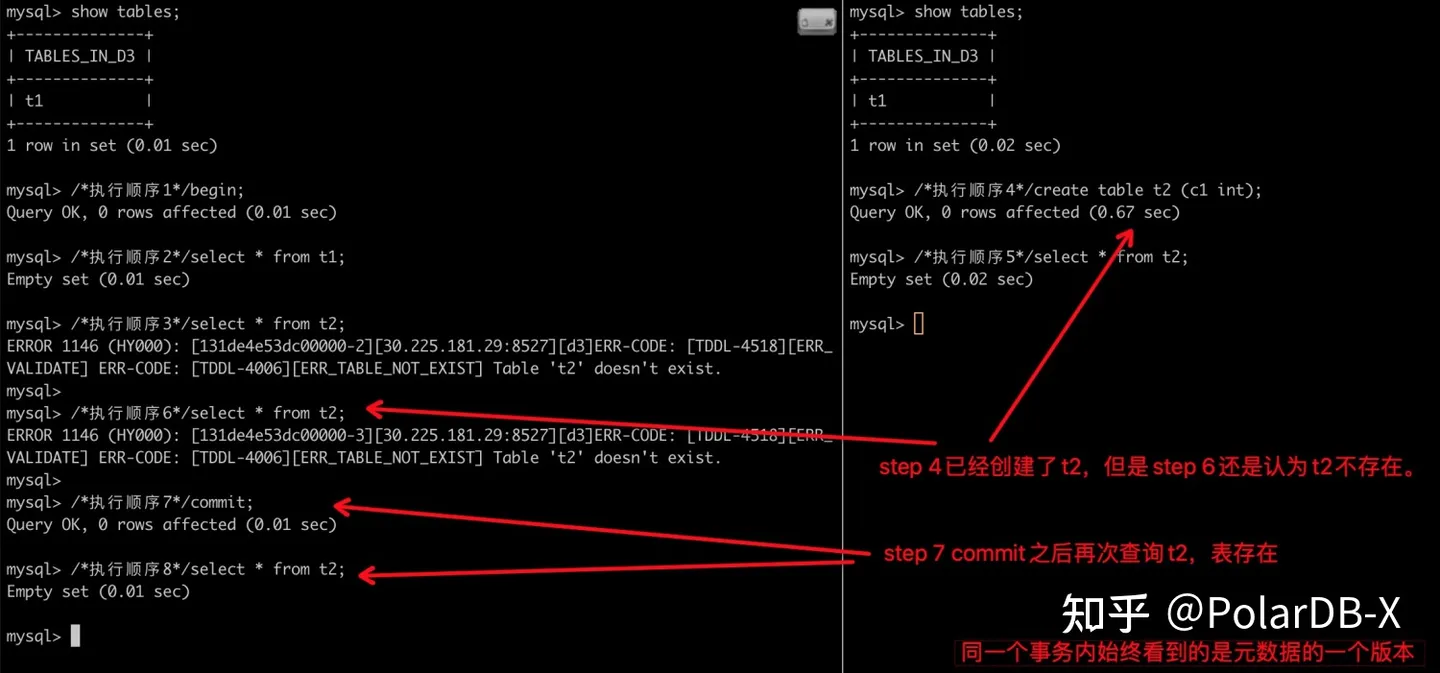
“一致性”实际上并不是一种“能力”,而是一个“目标”。如果不存在并发执行的情况,数据库没有BUG即可意味着保证了一致性,不在本文讨论范围之内。本文讨论的是:如何在DDL和DML并发、DDL和DDL并发的时候保证元数据和数据的一致性。 隔离性是保证并发执行时一致性的关键。 首先是DDL之间的隔离性。同一个表的多个DDL的并发执行的意义不大,所以DDL之间基本都是Serializable的语义。MySQL使用MDL锁确保不会对一个表同时执行2个DDL。考虑到上面讨论的Crash-Safe,PolarDB-X实现了一个轻量级的持久化的MDL锁,只用于DDL之间的并发控制。即便暂停了PolarDB-X的DDL任务,它还是会持有这个轻量级的持久化MDL锁。 然后是DDL和DML/DQL之间的隔离性。 如果一个事务内看到了不一致的元数据,显然很有可能造成数据错乱,引发奇怪的问题。所以最低要求是,事务内必须始终看到一致性的元数据。 这边有个设计取舍:我们是否允许同一个事务可以看到元数据的多个“一致性”的版本?还是只允许同一个事务看到元数据的一个“一致性”的版本? 我们先看看如果允许同一个事务可以看到元数据的多个“一致性”的版本,会发生什么。 (换句话说,事务内对元数据的变更是Read Committed的隔离级别) 假设我们现在有一个表T1,它只有一列c1,类型是INT。然后发生了下面的执行序列:
| Trx | DDL |
|---|---|
| begin; | |
| insert into T1(c1) values(1); | |
| alter table T1 add column c2 int not null; | |
| insert into T1(c1) values(2); | |
| commit; |
总结
回顾一下开头提出的DDL各种“罪状”,比如锁表、性能、Crash Safe问题。 PolarDB-X从ACID角度出发,分别给出了不同的解法,为DDL的online能力、Crash Safe能力、性能等都做了很多的优化,欢迎持续关注我们的文章。
参考资料
- PolarDB-X Online Schema Change
- PolarDB-X 让“Online DDL”更Online
- PolarDB-X 简介
- PolarDB-X 分布式MDL死锁检测